データ構造– tag –
-

線形探索と二分探索の違いと使い方
今日のトピックは「線形探索と二分探索の違いと使い方」です。どちらもデータ構造において要素を検索するためのアルゴリズムですが、それぞれに適した状況があります。 線形探索と二分探索の特徴を理解し、適切に使い分けることで、データ検索の効率を大幅... -
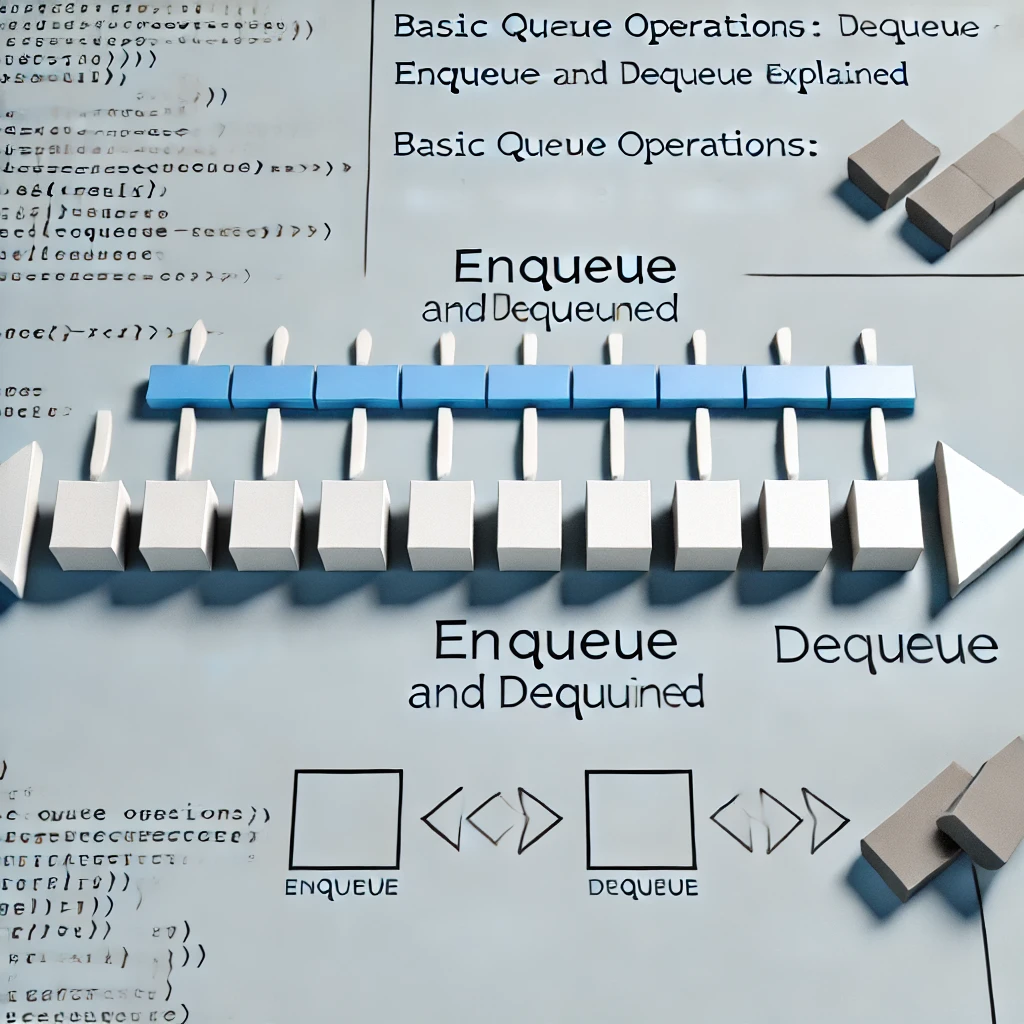
キューの基本操作(enqueue, dequeue)の解説
今日のトピックは「キューの基本操作(enqueue, dequeue)」です。キューは、FIFO(First In, First Out)に基づいたデータ構造で、最初に追加された要素が最初に取り出される特性を持ちます。 キューの基本操作である「enqueue」と「dequeue」を理解する... -
スタックの基本操作(push, pop)の解説
今日のトピックは「スタックの基本操作(push, pop)」です。スタックは、LIFO(Last In, First Out)に基づいたデータ構造で、最後に追加された要素が最初に取り出される特性を持ちます。 スタックの基本操作である「push」と「pop」を理解することで、こ... -
LIFOとFIFOの概念とその違い
今日のトピックは「LIFOとFIFOの概念とその違い」です。LIFO(Last In, First Out)とFIFO(First In, First Out)は、データの取り扱い順序に関する基本的な概念で、スタックやキューといったデータ構造で使われます。 これらの概念を理解することで、適... -
重複を許さないセットの特性と利用方法
今日のトピックは「重複を許さないセットの特性と利用方法」です。セットは、重複する要素を許さないデータ構造で、集合論に基づいた操作を効率的に行うことができます。 セットを利用することで、重複のないデータ管理や、データのユニーク性を簡単に確保... -
辞書のメソッドと使い方
今日のトピックは「辞書のメソッドと使い方」です。辞書はキーと値のペアを格納するデータ構造で、効率的なデータ管理や検索が可能です。各プログラミング言語には、辞書を操作するためのさまざまなメソッドが用意されています。 辞書のメソッドを理解し、... -
グラフの表現方法(隣接リスト、隣接行列)の詳細解説
概要: 今日のトピックは、グラフの代表的な表現方法である隣接リストと隣接行列についてです。これらの表現方法は、グラフアルゴリズムの効率性に大きく影響を与えるため、データ構造を理解する上で非常に重要です。 基本概念の説明: 隣接リスト 隣接リス... -
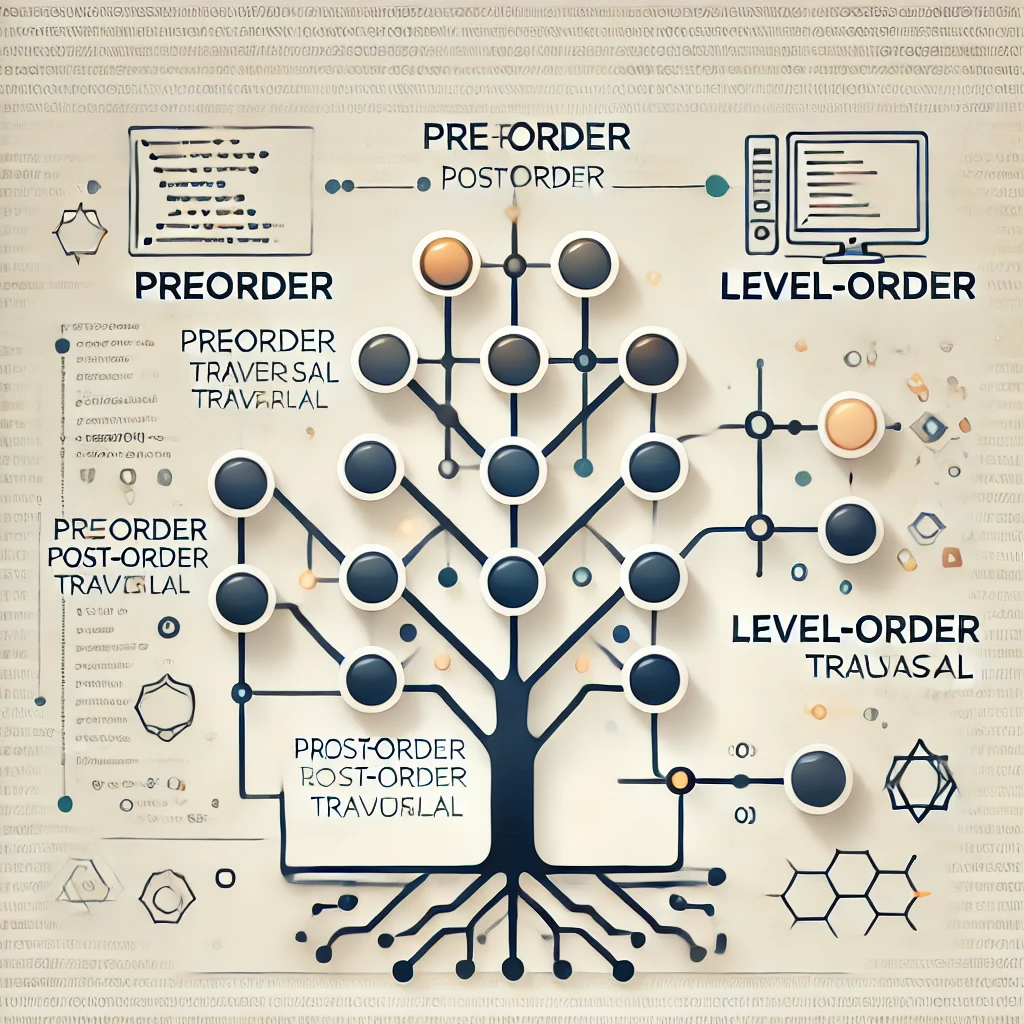
ツリーのトラバーサル(前順、後順、幅優先)の理解と実装
概要: 今日のトピックは、ツリーのトラバーサル方法、特に前順(プリオーダー)、後順(ポストオーダー)、幅優先(レベルオーダー)についてです。これらのトラバーサルは、ツリー構造のデータをさまざまな順序で処理するために使用され、アルゴリズムや... -
二分木、バランス木、B木の操作についての詳細解説
概要: 今日のトピックは、二分木、バランス木、B木の操作についてです。これらのデータ構造は、データの効率的な格納と検索に非常に重要です。特に、データベースやファイルシステムで頻繁に使用されます。 基本概念の説明: 二分木: 二分木は各ノードが最...







1